
I’ve been working for Red Hen Lab and CCExtractor as part of GSoC 2017. This year, my project was divided into three major components:-
- TV Commercial Classification – Details and code here (Done during June)
- Improving the visual recognition pipeline
- Optimizing the performance of the visual recognition pipeline and deploying it
Apart from this, I have also been working on analyzing and fixing issues with the CCExtractor code in order to better cater to some of Red Hen’s new international use cases.
In this post, I will describe what I have been up to this month, what things I have been spending my time working on, and some interesting decisions that I have had to make based on what I have observed in my experiments.
My Current Setup
Red Hen’s GSOC students have been working extensively on solving machine and deep learning problems which typically require a GPU for computational tractability. The Case HPC is where most of the important number crunching happens. However, being a shared resource, the HPC (and especially it’s GPU nodes) were not always readily available. I recently purchased a new laptop with a 4GB Nvidia GTX 1050 Ti GPU, which I have been using to work locally (as well as on my home institute cluster with more GPUs). Most of the benchmarking work that I have done have been on my computer, however the linearity of the observations and the computational power of other GPUs should hold for our particular use case of image classification (ie a more powerful GPU should take a linearly shorter time and a less powerful GPU a linearly longer time for the same use case).
Benchmarking ResNet for News Shot Classification
AlexNet (CaffeNet in our implementation) is the deep neural network architecture used for the shot characterization into 5 classes in the pipeline. This is a 7 layer deep architecture.
ResNet is a newer, deeper and more accurate model developed by Microsoft Research. It achieves state-of-the-art results on large scale visual recognition and is in essence a modern day upgrade to the 2014 CaffeNet architecture that we use.
Upon training ResNet on the same task with the same training/testing data split to identify news shot categories, the saturation accuracy of ResNet was superior. It achieves a peak accuracy of 93.7% whereas the AlexNet model achieves a peak accuracy of 88.3%. The ‘real’ accuracy (on exhaustive testing) for AlexNet is close to 86.5% and that for ResNet is close to 91%.
The training graph for the two architectures (done on a K40 GPU and a 1050 Ti GPU respectively) looks like this:-
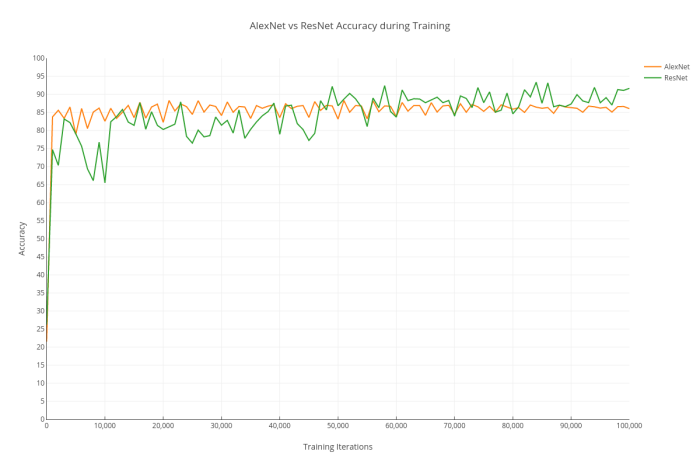
ResNet takes a slightly larger time to converge, likely because of the deeper architecture requiring more time for the gradients to flow across the network. But it achieves an overall accuracy of roughly 5-6% higher than the AlexNet model after training is complete. This is to be expected because the ResNet model is newer and more state-of-the-art. However, it’s extreme depth in terms of layers leads to a much, much higher time taken to train and test (predict new samples using) the model.
While running 100 iterations 10 times and averaging the time values for a batch size of 10 at test time, the benchmarks for my Nvidia GTX 1050 Ti 4GB GPU, and that for an Intel Xeon CPU node look something like this:-
| Model | Avg GPU Mode time (s) |
Avg CPU Mode time (s) |
| AlexNet | 7.34 | 283.66 |
| ResNet | 49.54 | 1812.31 |
My GPU seems to be around 3 times slower than a GTX 1080 judging by these benchmarks.
The final decision that I took on the basis of these observations was to stick to the existing AlexNet framework for the sake of speed on CPU nodes. An accuracy increase of 5-6% for the shot type categorization from an existing ~86% was good, but the tradeoff of 6-7 times the runtime was perhaps not ideal for our use case of processing over 300,000 hours worth of video.
Brazilian Timestamps and Deduplication
There was an issue with the Brazilian ISDB subtitle decoder which caused broken timestamps (Timestamps are the primary key for the Red Hen dataset, and without them, the data can’t be part of the searchable archive). There was also an issue with duplication
https://github.com/CCExtractor/ccextractor/issues/739
French OCR – Fixing an Issue with Image Transparency
https://github.com/CCExtractor/ccextractor/pull/759
This one was one of those problems that happened to be a one line fix, but involved a huge amount of analysis, reading and experimentation to get done right. It took me the good part of a week to get this to work as it is now, and hopefully this yields near perfect OCR results for all use cases, including those with transparent DVB subtitles.
Adding GPU specific usage to the Visual Pipeline
Earlier, the pipeline was supposed to be run as one single job on a CPU compute node, and even if the requested node was a GPU node, the capabilities of the GPU would not be used by it. I added the capability to use a GPU if available. If no GPU is available (or detected by the code), we fall back to default CPU execution.
The changes to make this happen can be seen at:-
https://github.com/gshruti95/news-shot-classification/pull/2
This is especially useful in speeding up the runtime of the feature extraction and classification steps that involve deep neural networks (namely anything that invovles running a Caffe model). GPU execution of these steps speeds up the runtime by an exponential factor which could be anything between 20 to 200 times depending on the individual computational power of the CPU/GPU in question. On my computer, a nearly 40 times speedup can be observed (benchmarks above).
Upgrading the YOLO person detector in the Visual Pipeline to YOLOv2
The current pipeline has the YOLO object detector specifically for person detection. However, YOLO was upgraded to YOLOv2 this year and has been accompanied by significant accuracy gains. I upgraded the version of YOLO used in the pipeline to the latest one, while retaining the same output format in the SHT and the JSON files.
I integrated the original C code based on Darknet for YOLOv2 to the pipeline, and person detection results are slightly better than before.
Singularity Container for Portable HPC Execution of the Visual Pipeline
Singularity is an HPC friendly alternative to the popular Docker framework. Red Hen has been heavily using Singularity this GSoC. One particularly useful use case is portable usage of the Singularity image on multiple HPC clusters (e.g. Case HPC, one of the many clusters at Erlangen HPC etc)
I have written a basic singularity image for the state of the code at this moment, which creates a container and then downloads all required models and dependencies, and sets up the container for usage of the visual recognition pipeline.
Upcoming Work
In the final third of GSOC, I will work on reducing the overall runtime of the pipeline by as much as possible. I will also work on writing an HPC job manager script which logically segments the different parts of the pipeline and submits and tracks different jobs for each based on available resources (GPU/CPU). Another thing to do is set up the pipeline with CPU optimized Intel Caffe which will allow automatic parallel processing on CPU nodes on HPC. After doing this and testing for sanity, the pipeline should be ready to be put into production on the entire NewsScape dataset, perhaps on multiple HPCs.
